对于好奇心机制的一个小随笔😄😄
好奇心学习概述:概念和方法
好奇心理论:认知与神经科学
什么是好奇心
- 好奇心是我们获取新的信息的一个愿望
- 好奇心是去探索新颖的、不确定的、复杂的、模糊的事件的一个愿望
好奇心的分类:
Grossnickle, Emily M. "Disentangling curiosity: Dimensionality, definitions, and distinctions from interest in educational contexts." Educational Psychology Review 28.1 (2016): 23-60.
- Physical curiosity:针对自身及周围事物进行探索
- Perceptual curiosity:基于新颖的(视觉、听觉)激励信号探索新信息
- Social curiosity:利用语言询问和探索原因求助于其他人获取新信息
- Intellectual/epistemic curiosity:激发获取新感知和学习新知识的愿望(主动提出问题,并解决问题的方式)
好奇心中的四个变量
Wu, Qiong, and Chunyan Miao. "Curiosity: From psychology to computation." ACM Computing Surveys (CSUR) 46.2 (2013): 1-26.
- Novelty:对于个体而言比较新的内容。也表现为变化、惊奇
- Uncertainty:个体面对一个激励信号时难以选择一个合适的相应
- Conflict:一个激励信号出现两个或多个不一致的相应
- Complexity:一个激励信号内模式的多样性(比较抽象,探索较少)
好奇心的特性:
- 高度好奇心会使人对一些细微的事物和不熟悉事务的记忆更佳
- 好奇心与年龄呈负相关关系,年龄越大,其选择性越强,但是探索和好奇减弱;更有限的未来时间使得好奇心重要性的降低
- 好奇心受环境因素影响,高度好奇心有助于学习的持续性
好奇心的潜在问题:
- 不良习惯和嗜好的探索
- 过度好奇会使人奇怪
- Exploration vs. Exploitation
- 高失误可能性
- 特定场景中的不当好奇
强化学习中的好奇心建模
强化学习的奖励函数:
奖励函数通过是否完成最终任务目标给予智能体反馈
主要奖励函数往往在最后才能进行反馈
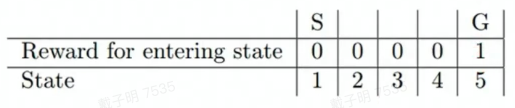
如图,像围棋一样,只有最后才能知道胜还是负,这就会出现奖励信号稀疏问题,导致强化学习无法收敛
所以我们就不仅仅需要外在奖励,更需要一个内在奖励(根据所处环境,自发得到)
eg.
我想得到奖学金,每年最后的获奖是外在奖励;但是中间过程我要主动知道去学习,去从学习中获得乐趣和成就感,这就是内在奖励
内在驱动奖励函数
基于计数的内在驱动奖励函数
Bellemare, Marc, et al. "Unifying count-based exploration and intrinsic motivation." Advances in neural information processing systems 29 (2016).
Ostrovski, Georg, et al. "Count-based exploration with neural density models." International conference on machine learning. PMLR, 2017.
- 鼓励智能体去探索未经历的状态,抑制其反复学习已经历的状态
- 对经历过的状态进行计数,作为奖励的数值
基于自监督预测的好奇心驱动搜索
Pathak, Deepak, et al. "Curiosity-driven exploration by self-supervised prediction." International conference on machine learning. PMLR, 2017.
好奇心的作用:探索环境以获得新知识;促进智能体学习对未来有帮助的新技能
好奇心应当使得智能体只预测环境中可能由于智能体的行为或影响智能体而发生的变化
构造一个特征空间,只建模对智能体动作相关的信息
使用正向、逆向两个网络来表示特征空间
- 逆向:给定智能体当前和下一个状态的情况下预测智能体行为(\(State_0 + State_1 \to Action\))
- 正向:给定当前状态和行动的表示下预测下状态的特征表示(\(State_0 + Action \to State_1\))
好奇心:当前状态特征和下一个状态特征的差异值
随机网络蒸馏:差异值可以用一个随机初始化的固定网络
Burda, Yuri, et al. "Exploration by random network distillation." arXiv preprint arXiv:1810.12894 (2018).
面向目标任务的好奇心度量:
问题:如果有一个随机的新颖状态,模型将会永久停留在那里)
Savinov, Nikolay, et al. "Episodic curiosity through reachability." arXiv preprint arXiv:1810.02274 (2018).
所以我们需要多步探索,才能观测到的状态进行奖励(橙色部分)
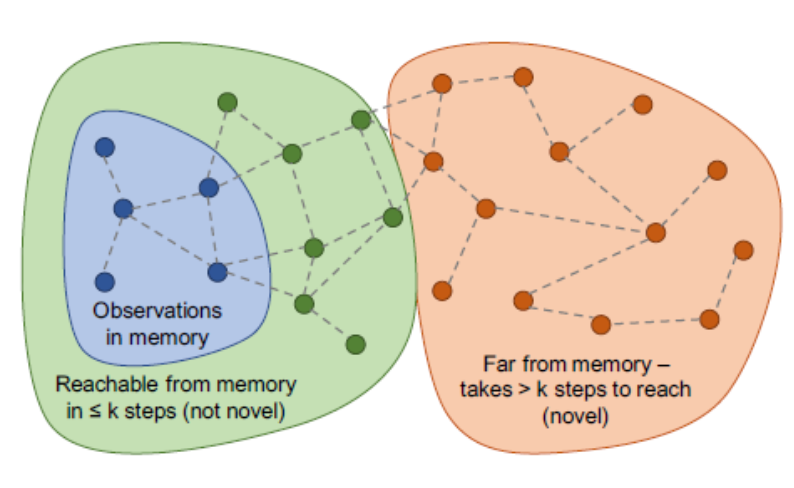
- 节点是观测状态
- 边是转移状态
- 绿色:很简单就能达到的状态
- 橙色:比较复杂(大于两步)达到的状态
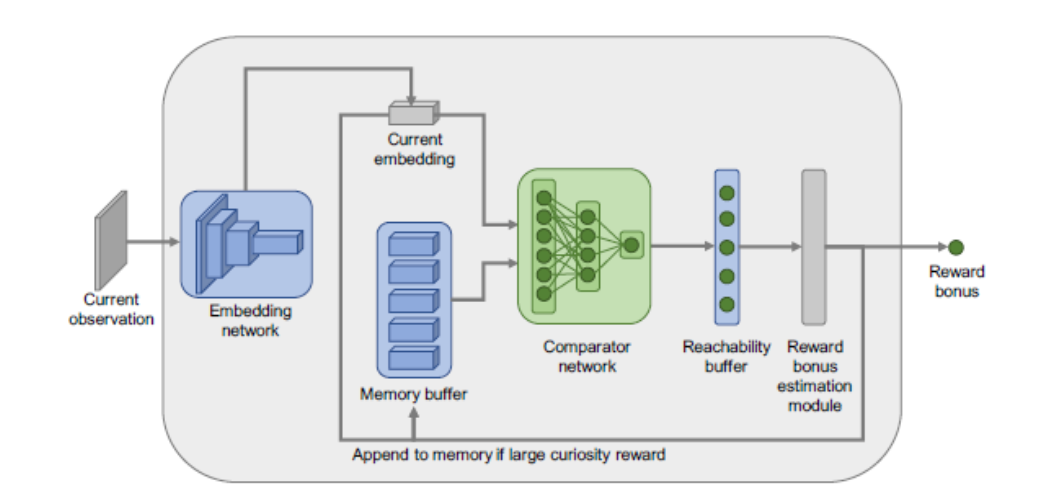
通过比较网络来判断这个状态是否值得学:使用对比学习
- 正例:两步以内能达到的状态
- 负例:多步才能达到的状态
对当前的观测与memory内部的观测进行可达性分析,如果在橙色的部分,那么就给一个很高的reward
影响驱动的内在奖励建模:
Raileanu, Roberta, and Tim Rocktäschel. "Ride: Rewarding impact-driven exploration for procedurally-generated environments." arXiv preprint arXiv:2002.12292 (2020).
我们不能随意去关注内在的奖励,而是要看看他最后的影响是什么。
如果state差异过大了(比如游戏中不同的关卡),这个时候没有办法预测,所以我们要根据最终的影响来对奖励函数建模
基于技能的好奇心建模方法:
Bougie, Nicolas, and Ryutaro Ichise. "Skill-based curiosity for intrinsically motivated reinforcement learning." Machine Learning 109.3 (2020): 493-512.
动机:解决高维状态空间的模型训练问题
方法:将实现目标的能力定义为技能,把最终任务(胜负)分解为多个简单的子任务(目标)
奖励函数鼓励智能体学习那些难以学习的技能,行动——状态空间同时新颖性较高的区域。
基于惊奇的内在奖励建模方法:
Berseth, Glen, et al. "Smirl: Surprise minimizing reinforcement learning in unstable environments." arXiv preprint arXiv:1912.05510 (2019).
在不断变化的场景下,减少过大的扰动,保持稳定平衡相比于探索来说更具有挑战性
总结
- 好奇心在认知学、神经科学等领域广泛研究的一项人类特质,已经被广泛认可为有助于持续学习和探索的一项基本能力
- 在人工智能领域,好奇心主要用来对新事物或观测进行探索的一种建模手段和激励机制
- 强化学习由于监督信息系数的问题,借鉴了好奇心原理,作为内在奖励函数建模与设计的一种重要手段
- 在其他领域如分类、检测中,好奇心的应用尚未得到广泛应用
- 如何有效利用好奇心的优势同时规避其可能带来的负面问题,是未来的重要课题
思考
好奇心包括了不确定性(uncertainty),学习是为了去消灭不确定性
不确定性:不确定性与物体出现的次数有关,激励信号应该不断强化。
eg.碰到一个陌生人,并不会好奇;但是如果天天碰到这个陌生人,就会好奇他是谁
所以想法:可以利用好奇心机制去解决一些离散点。如果第一次碰到误差大的就应该给一个好奇心,如果反复出现这样的样本就应该去学习,以为可能是一个特例。