🎉🎉🎉 热烈祝贺人生第一篇CCF会议:GLOBECOM 2023 GCSN 中稿!——2023.08.04 🎉🎉🎉
MG²FL: Multi-Granularity Grouping-Based Federated Learning in Green Edge Computing Systems
简单总结一下文章思路、问题以及扩刊方向。
论文对应的痛点及解决方式
联邦学习多用在了分布式的设备上,比如说无人机、无人汽车、移动机器人等。这是因为联邦学习在解决了隐私问题之外,其最大的好处是利用了分布式的数据和分布式的算力。所以移动边缘设备成了非常适合联邦学习应用的设备。但是,这些移动边缘设备一般会面临着几个问题:
- 能耗问题:由于是移动设备,每个设备的电池电量是有限的,无法进行长时间高能耗的机器学习任务。
- 通信问题:对于移动的边缘设备,每个设备分布较为离散,相距较远的设备可能会出现通信延迟等问题,会严重减慢联邦学习的收敛速度。
- 异构问题:由于分布离散且不均匀,移动边缘设备所拥有的数据集和模型都是异构的,这不利于传统联邦学习聚合。
- 恶意问题:这个系统中可能会出现故障或恶意节点影响全局模型。
对于以上三点,文章提出了MG²FL,创新点如下:
- 依托设备之间的通信开销以及指导效果进行构图,并利用平衡图分割获得群组设备性能相近的平衡图,同时保证了图之间的设备通信开销较低且指导效果较高。
- 利用知识蒸馏的方式将拥有细粒度、大模型的设备的知识转移给拥有粗粒度、小模型的设备。从而使得在较短的训练周期中小模型获得更高的模型性能。
- 采用了信用分聚合方式,对每个设备信用分动态调控,从而控制其聚合权重来减少恶意行为的影响。
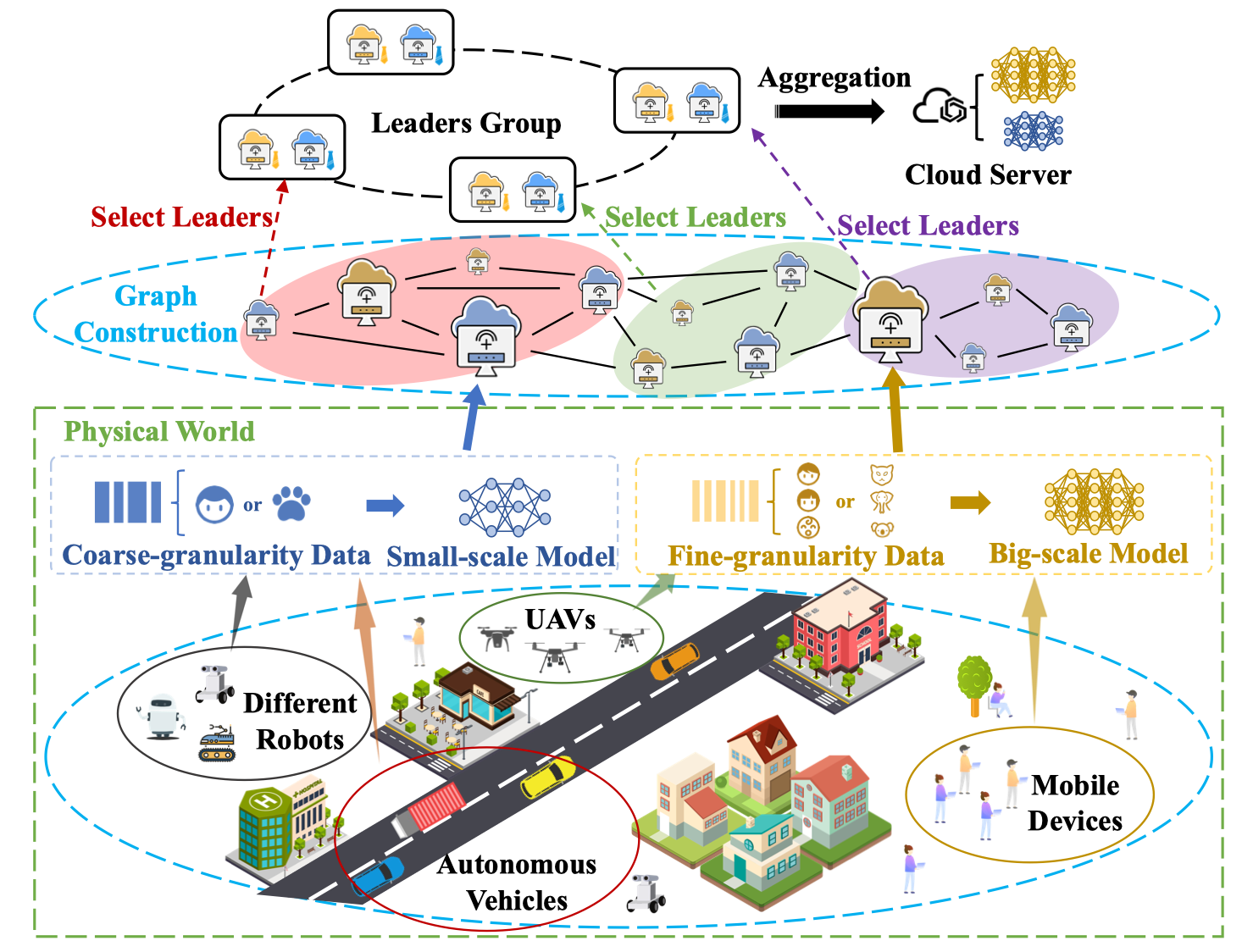
模型构建
通信开销(延迟+传输能耗)
通信延迟 \[ t_{ij}^{latency}= d_{ij}/v \] 这里的\(d\)是两个边缘设备之间的距离,\(v\)是信号传输速度。在这里并没有考虑模型参数的传输速率,仅仅考虑了传播速率。
传输能耗
传输能耗采用了香农公式: \[ r_{ij}=B_{ij}log_2(1+\frac{g_{ij}p_{ij}}{N_0B_{ij}}) \] 这里的\(r\)是数据的传输速率,传输时间为:\(T_{ij}=|d|/r_{ij}\),这里的\(|d|\)为传输数据量的大小,那么最后的传输能耗如下,其中\(p\)是传输功率: \[ E_{ij}^{trans}=p_{ij}T_{ij} \]
模型指导(蒸馏)
我们定义了模型指导能力\(\pi\): \[ \pi_{ij} = \varphi(w_i,x_j, y_j)-A_j \]
\[ \varphi(w_i,x_j, y_j)=\frac{\sum_{k=1}^{|x_j|}\mathbb{I}_{\{H\cdot p(w_i,x_{j,k})=y_{j,k} \}}}{|x_j|}, \]
\(w_i\)为\(i\)的模型参数,\(x_j\)为\(j\)的数据特征,\(y_j\)为标签。
其实就是看Teacher \(i\) 在 \(j\) 的公开数据集上的预测精度比Student \(j\) 的预测精度高多少。预测精度差距越大,说明这个Teacher能力越高,其作为老师的意义越大。
信用模型
信用分数用来衡量边缘设备的可信性,可信性越高,我们认为其应该在聚合中的影响越高。初始的信用分数用其各自的数据量大小和计算性能来确定,之后动态的部分利用其在模型参数在服务器的测试数据集上的精度进行动态调整 \[ C_i=\log\frac{D_i}{\sum_{i=1}^{N}D_i}+f_i + c_i^I \]
\[ c_i^I=\sum_{k=1}^{I}{1}/\{1+e^{-log(c_i^{k-1}+a_i)}\},\quad c_i^0=0 \]
如此设计,在聚合过程中上传恶意参数以及不上传参数的模型的信用分数会不断降低,其在聚合中的影响会越来越小。
算法部分
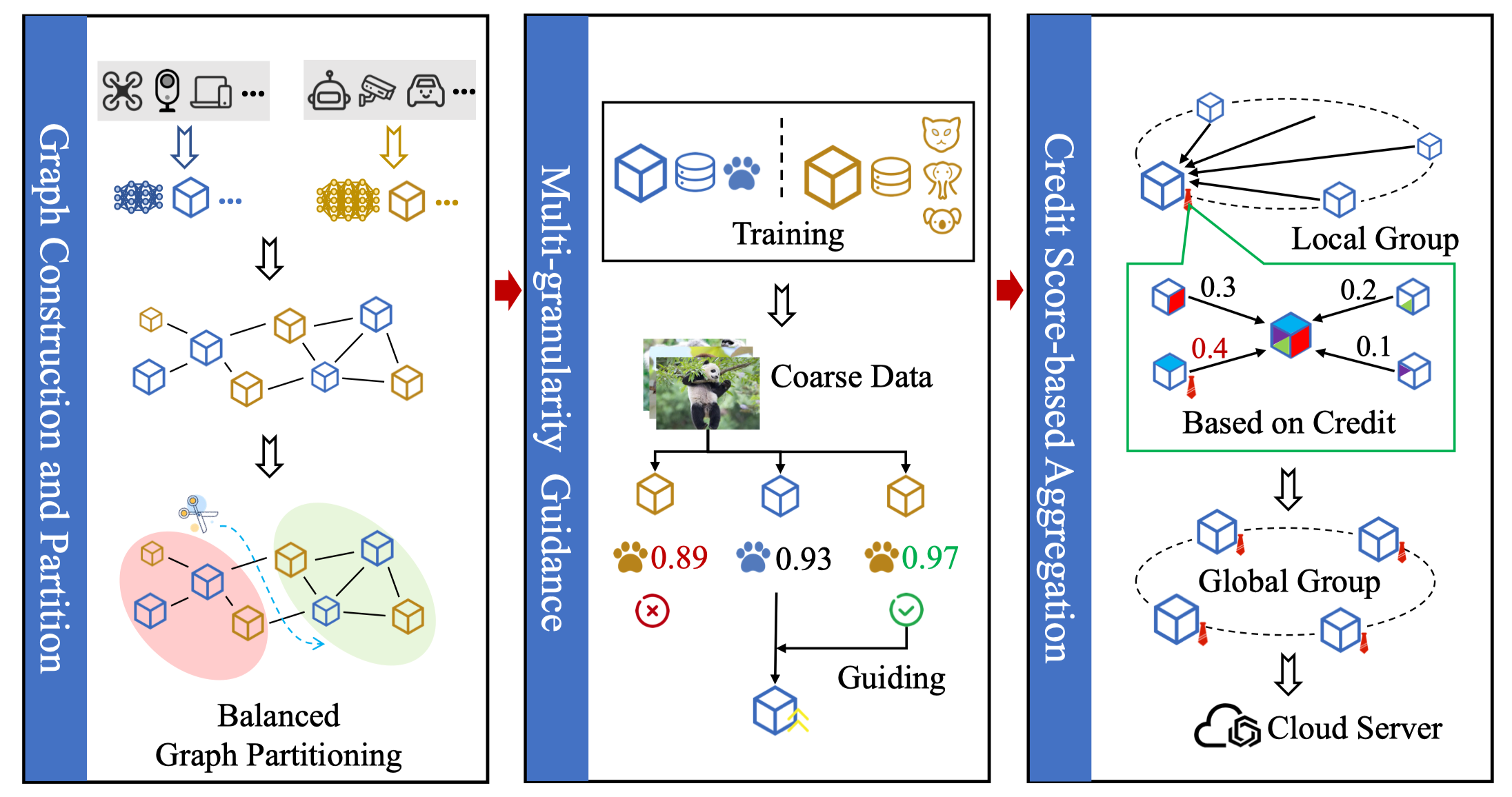
测试训练
在最开始,每个边缘设备进行自己的测试训练,这里训练采用较小的数据集进行训练,同时epoch可以设置的比较低。这个阶段主要是测试每个边缘设备的计算能力、统计其数据量以及计算各个设备之间的指导能力等,为之后的图构建做准备。
图构建
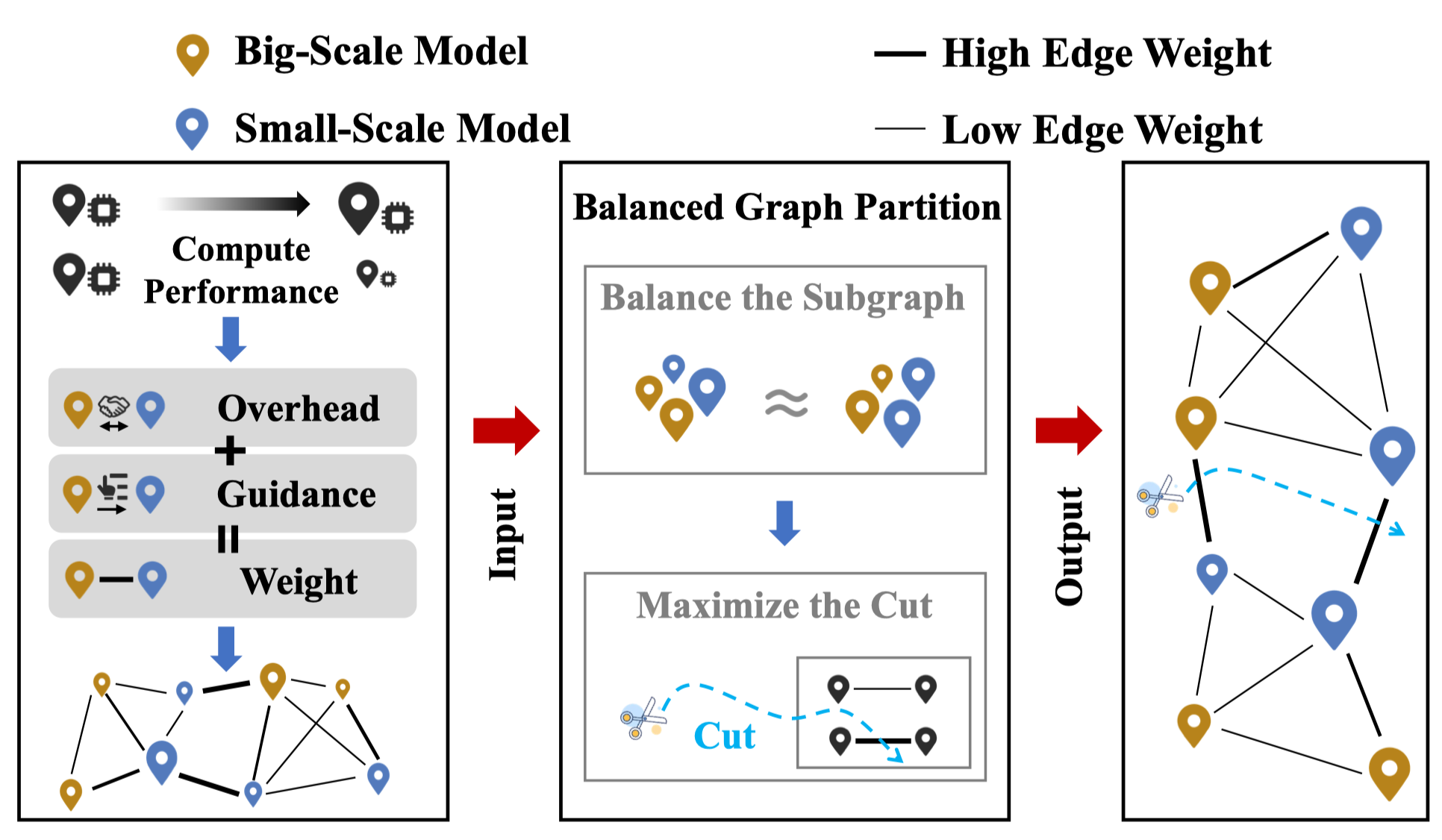
如图中所示,因为我们的目的是构建一个平衡图,每个子图的节点性能要相近,同时在图分割之后,每个子图中的设备之间的通信开销要较低,且指导能力要强。
我们对于每个节点的权重定义为其数据集大小和设备性能:\(W_{i} = ({\gamma t_i +\frac{1}{1+e^{-D_i/f_i}} })/{2}\)
对于边的定义为(\(e_{ij}\)越低越好,所以将\(\pi\)去倒数来统一单调性): \[ e_{ij} = \nu\frac{1}{\pi_{ij}}+ \varsigma t^{latency}_{ij}+ \tau E^{trans}_{ij}, \ i > j \]
因此我们使用了平衡图分割算法KaHypar,这个算法会将图粗化并进行平衡分割,之后在进行图细化。分割后每个子图的权重会很相似。 \[ \max\limits_{s_k\in\mathcal{S}}|V_{s_k}|\leq(1+\varepsilon)\frac{\sum_{s_k\in \mathcal{S}}|V_{s_k}|}{|\mathcal{S}|} \] 同时该算法会切割权重最高的几个边来构建平衡图,这就使得文章最后得到的图中通信开销较高且指导能力较弱的边都被切割掉了。
模型指导
每个设备会存储在测试训练中所有对其指导的设备的指导能力参数\(\pi\),在模型指导环节,每个设备会选择在组内的指导能力最强的设备进行指导操作。 \[ w_i=w_i - \eta\alpha\bigtriangledown\zeta(M_i,M_j) \]
\[ s.t.\quad j=\arg\max\ \pi_{ij},\quad j\in N(i) \]
信用分聚合
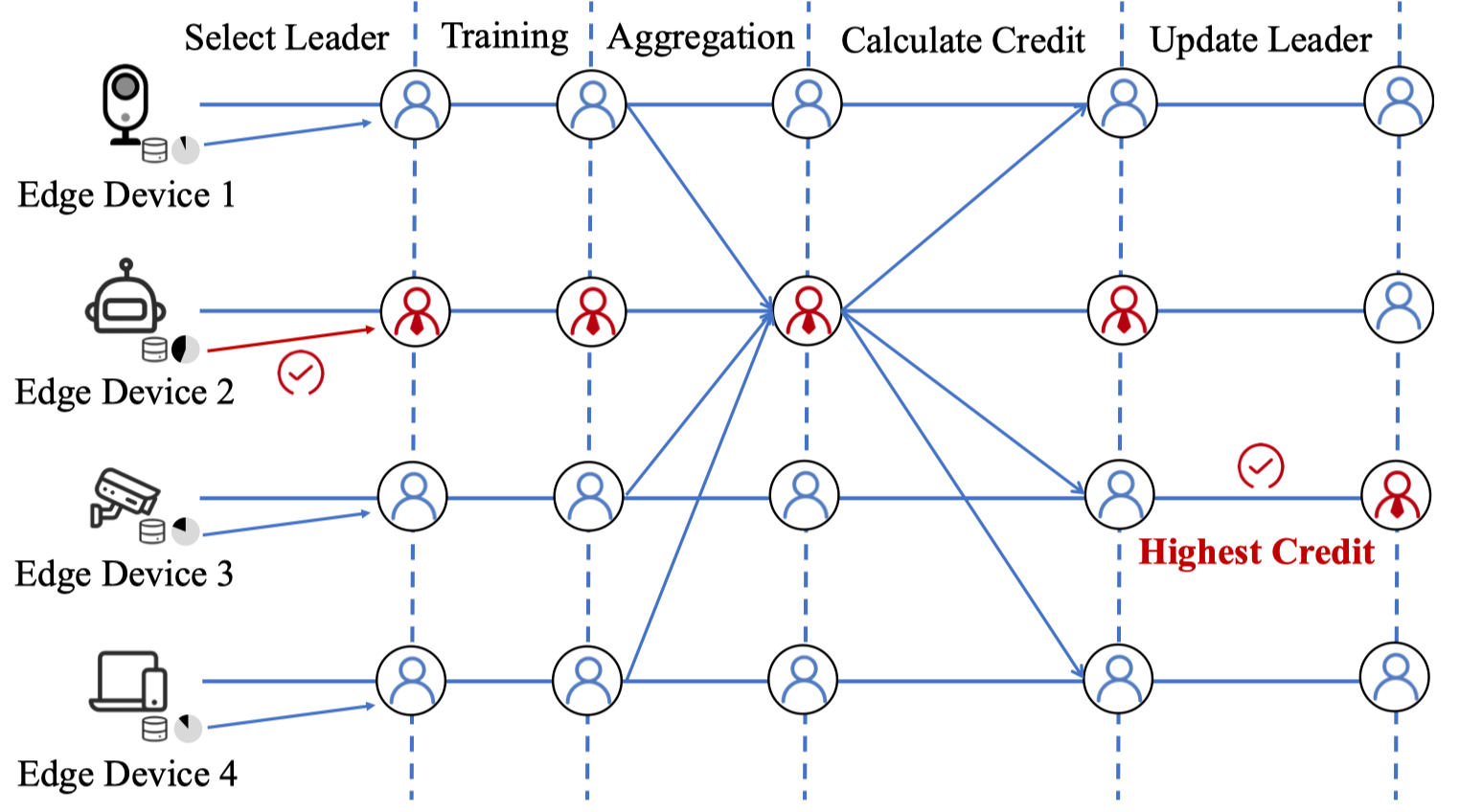
简单来说就是每个边缘设备进行训练结束后,会将自己的模型参数上传到leader,leader会利用自己的测试数据集对每个模型参数进行测试,利用其准确率更新每个边缘设备的信用分,然后利用信用分进行聚合。随后选择信用分最高的边缘设备作为下一次的leader。
总体来说,就是整个系统分成了两层,每个边缘设备被分到了一个群组中,由于文章考虑了两种不同的模型,所以每个群组会有两个leader,这个leader一定是该模型中信用分最高的设备,然后每个群组在leader上聚合后,每个群组的leader会进行最后的聚合来获得最终的全局参数。

审稿意见
- 通常,传播延迟可以忽略不计,因为微波的传播速度非常高。传输延迟不应该与能量消耗结合起来。它应该是优化中的独立约束。
- 应提供(4)中的详细函数。
- 应讨论所提出算法的复杂性。
- 图5在当前版本中很难遵循。最好重新整理一下。评估的指标应标记在 y 轴上。
- 鼓励作者添加有关调度算法和恶意检测技术的其他参考文献,以提供全面的背景并展示该领域的现有方法。这将有助于建立背景并突出所提出方法的新颖性。
- 进行模拟并展示结果对于证明所提出的方法相对于以前的方法的有效性和优越性至关重要。通过与现有方法进行性能比较,作者可以展示他们提出的算法所实现的优势和改进。
- 对于作者来说,清楚地解释在设计算法时结合基于图的技术背后的动机非常重要。他们应该强调图表提供的优点和好处,例如捕获复杂的关系,促进有效的信息共享,或实现有效的决策。通过为图表的使用提供清晰的理由,作者可以确定其方法的相关性和潜在影响。
- 添加更多有关基于 FL 的边缘计算中的恶意行为的参考。
- [9]似乎没有提到联邦学习。[10]还提出了多粒度指导FL来增强性能,那么这项工作和ref有什么区别呢?作者应该给出更多的解释。
- 作者应详细解释模拟结果。在第 5 页,本文中的数字有点混乱。1) 图6(a)中缩写“SD of EP”中的“EP”指的是什么?2) 图 7 (b) 中的“目标”指标代表什么?3)此外,作者在本文中没有介绍基线。
- 结论不完整,没有充分阐述本文的意义。
- 建议添加图2和图3的额外描述,以提供更清晰的MG2FL框架概述。
- 模拟部分缺乏对所使用的三个基线的充分解释。
- 图5中的标签看起来很混乱。
- 当epoch在 100 到 125 之间时,图 7(a) 中观察到了明显的差距。有必要对这一差距提供全面的解释,以更好地理解其原因和含义。
- 论文缺乏Mg2FL与信用模型收敛速度的数学推导,这将为信用定义的有效性和可靠性提供必要的支持。包含这样的推导将提高论文的可信度并强化所提出的方法。
扩刊方向
暂略…