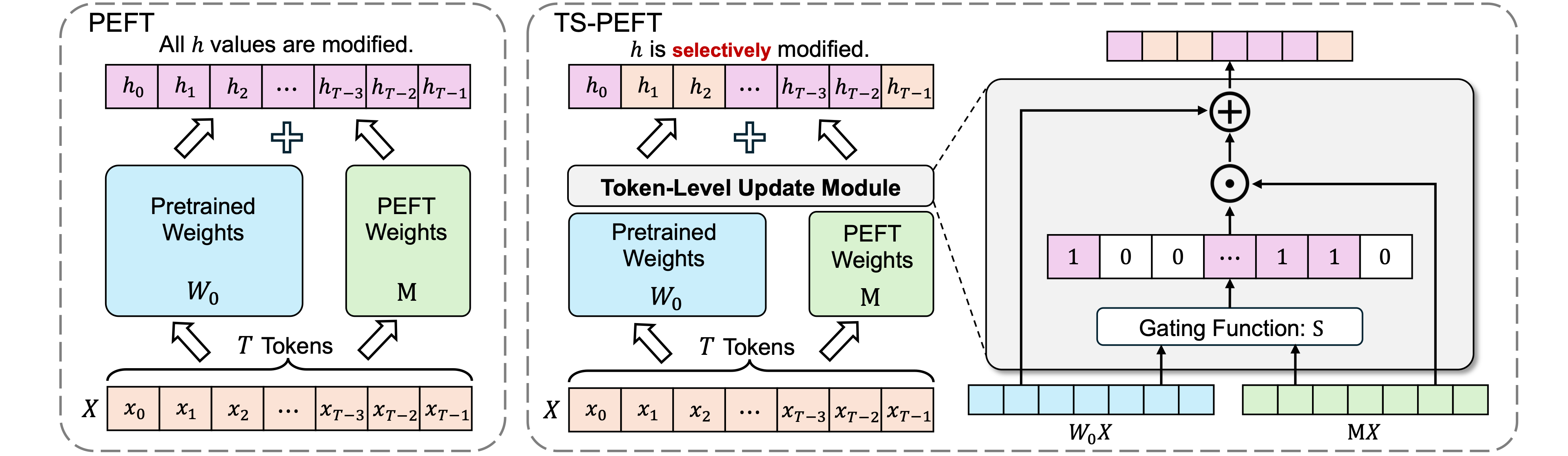
TS-PEFT: Unveiling Token-Level Redundancy in Parameter-Efficient Fine-Tuning
A token-level sparsity perspective for reducing redundant updates in parameter-efficient fine-tuning.
PEFT Token Sparsity LLM Fine-Tuning

A token-level sparsity perspective for reducing redundant updates in parameter-efficient fine-tuning.
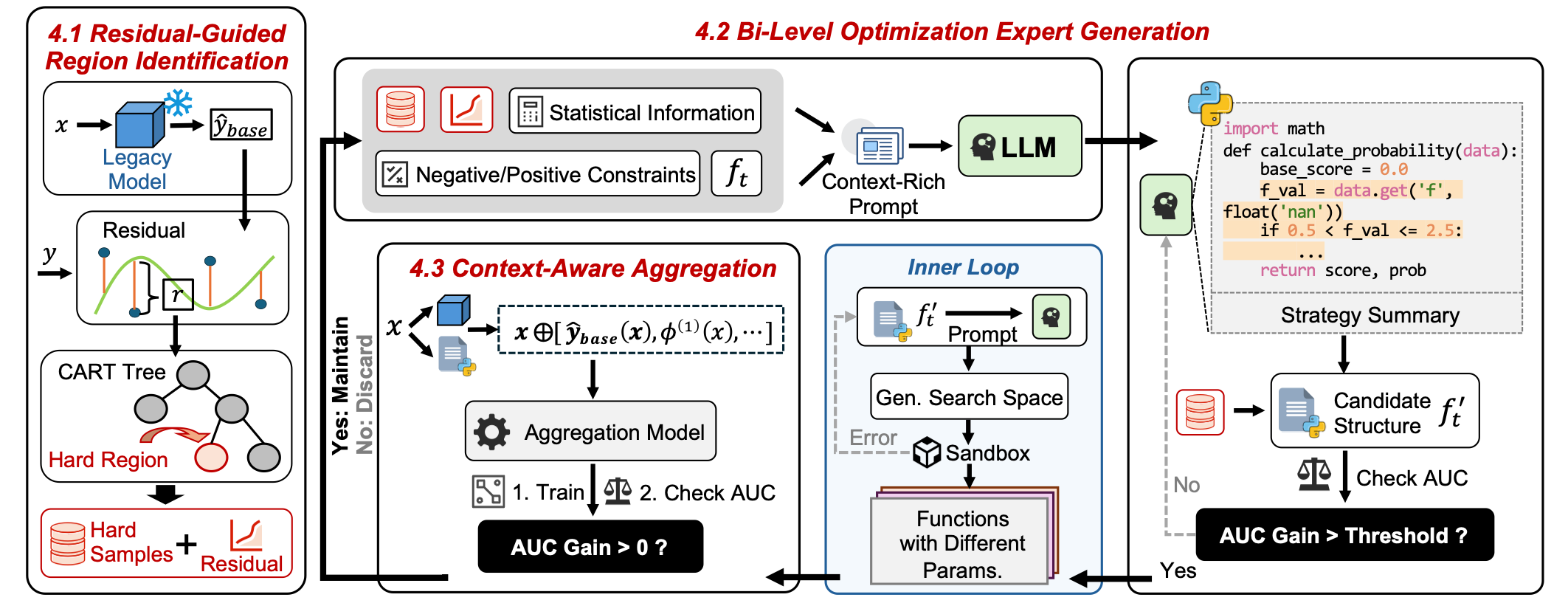
A neuro-symbolic residual boosting framework for upgrading industrial legacy models without full retraining.
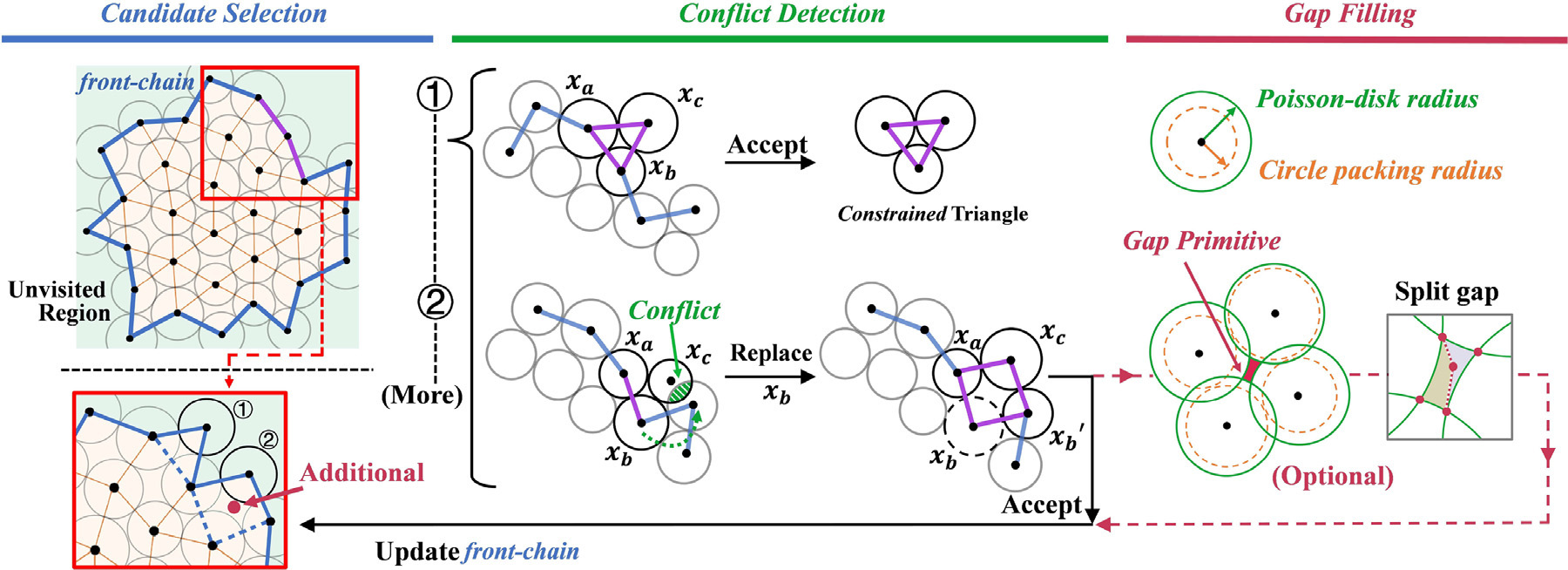
A single-pass Poisson-disk sampling method via circle packing for efficient blue-noise sample generation.
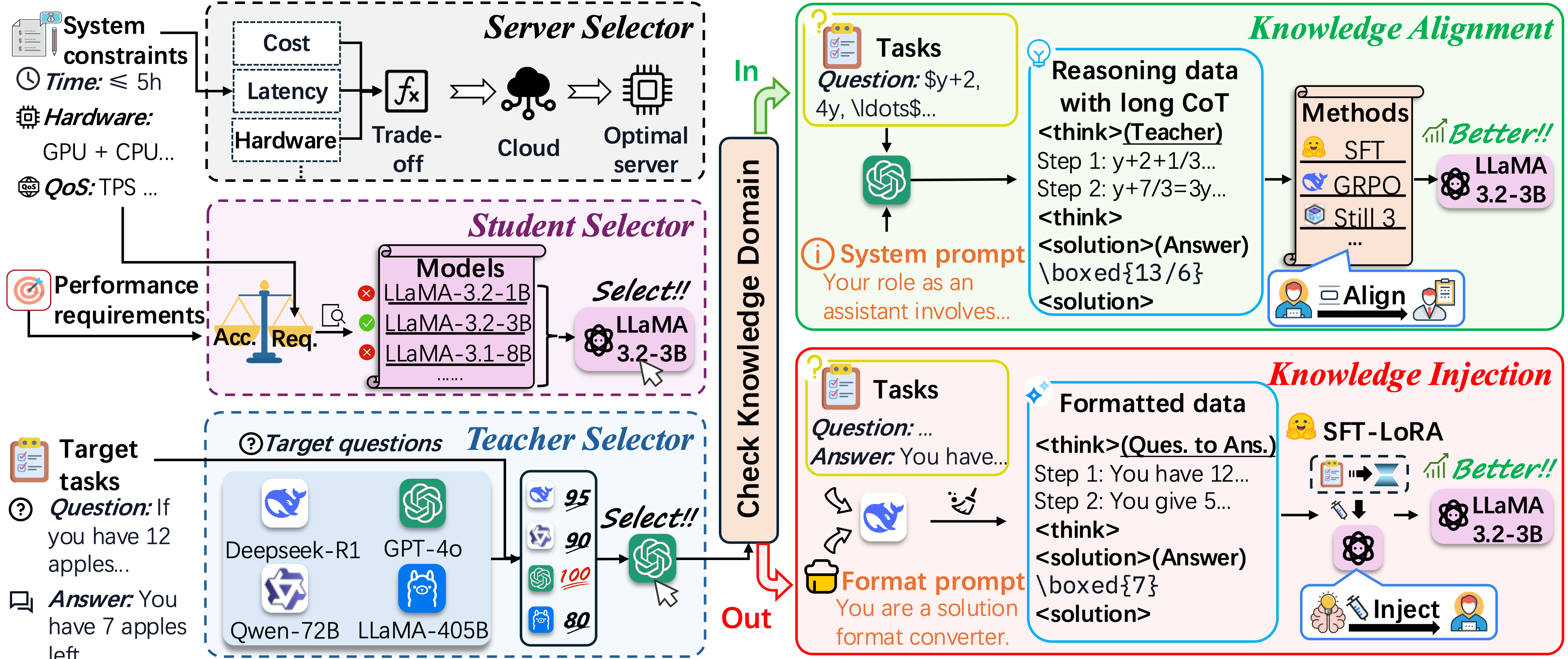
An end-to-end distillation pipeline for customized LLM deployment under distributed cloud constraints.
A distributed customization system for adapting large models while reducing centralized training cost.
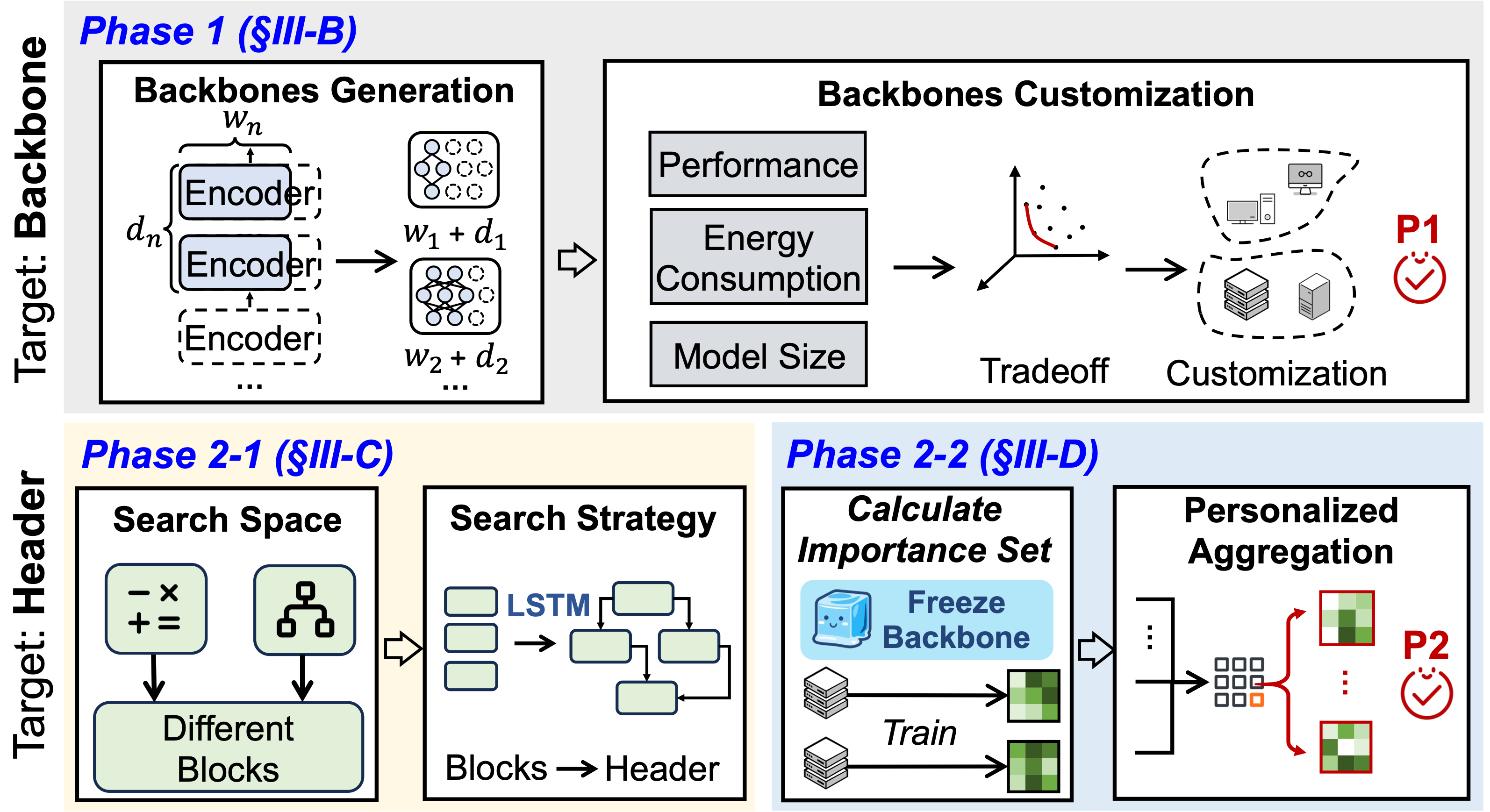
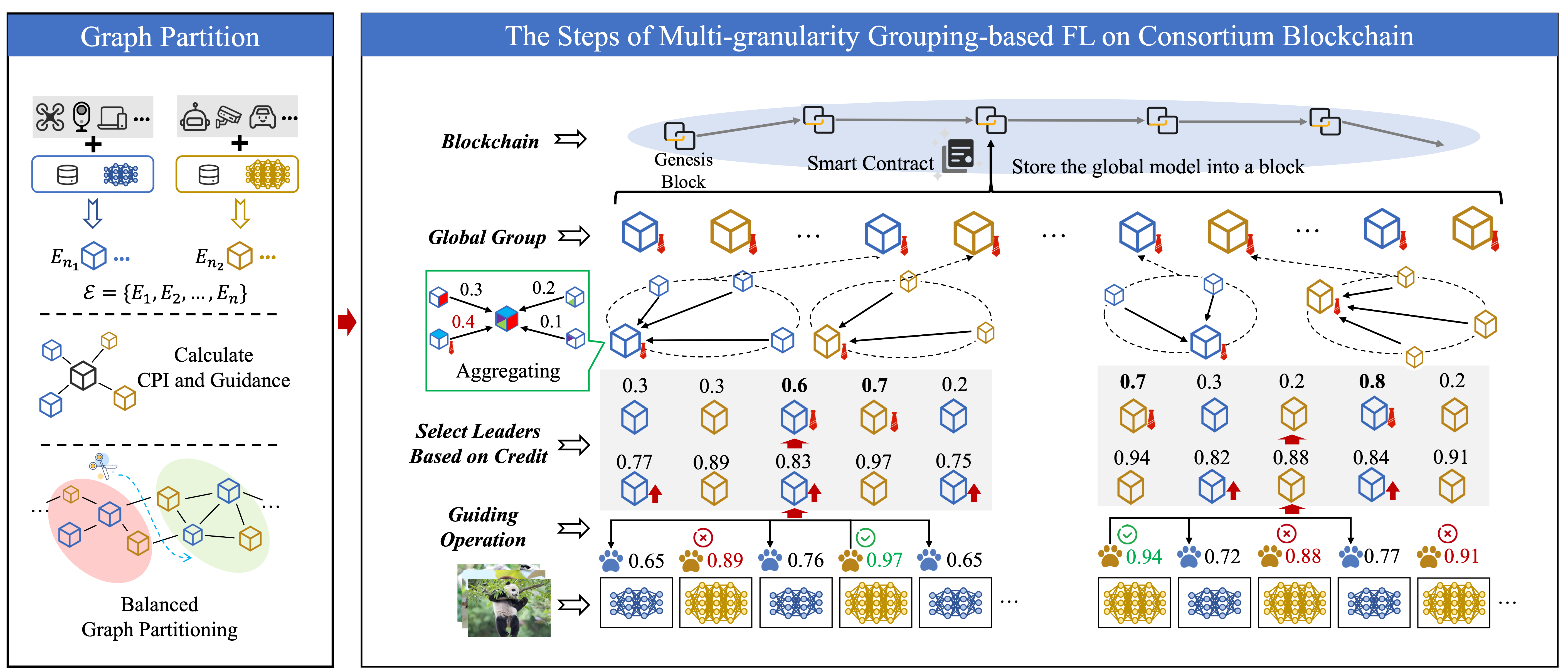
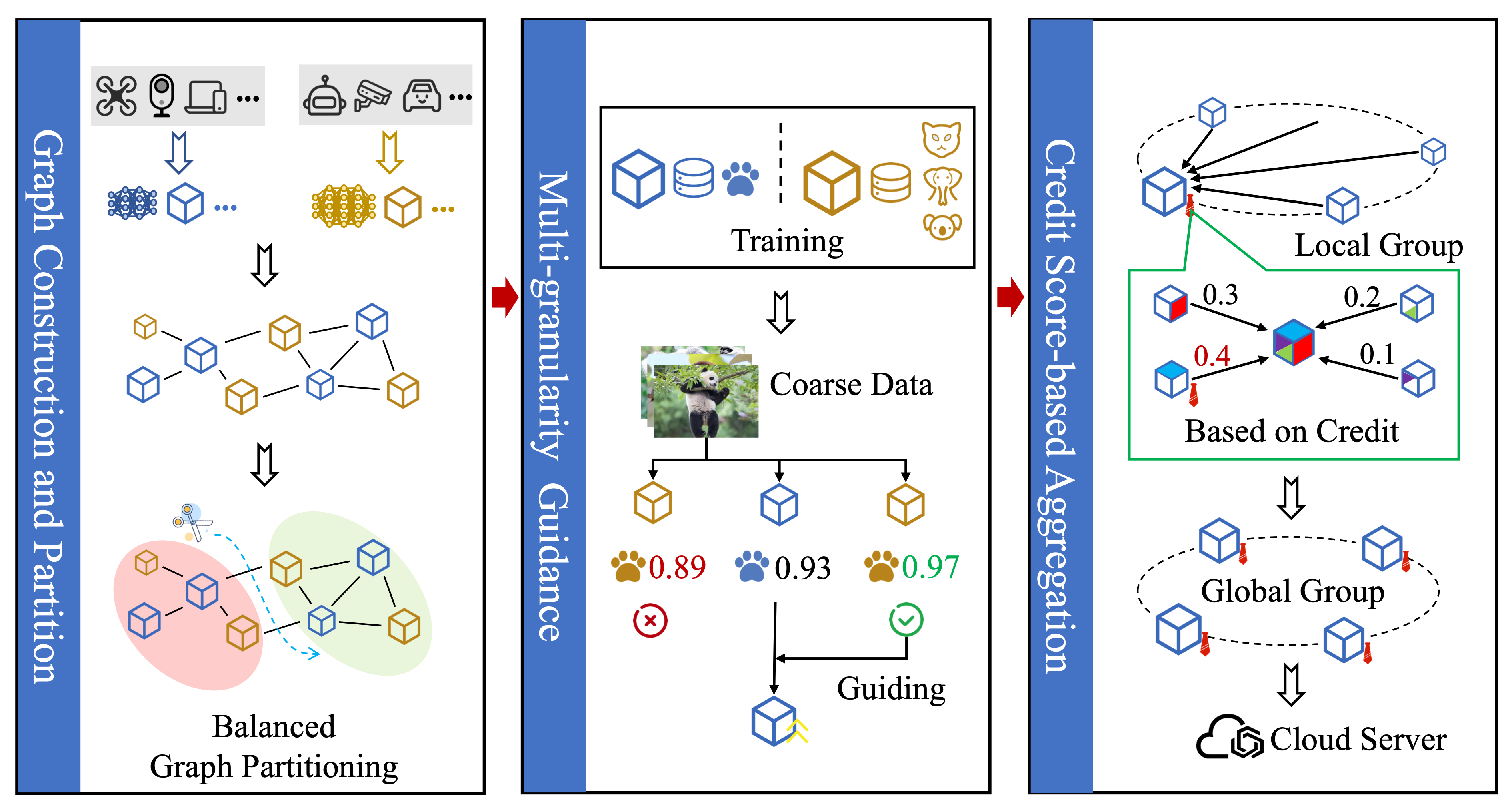
A graph-partitioning multi-granularity federated learning method for efficient and robust edge collaboration.
A multi-granularity grouping framework for improving federated learning efficiency in green edge systems.
An AI-driven resource provisioning approach for 6G immersive services across region-temporal demand.